

Recently, a new trend has emerged in the world of ransomware: intermittent encryption, the partial encryption of targeted files. Many ransomware groups, such as BlackCat and Play, have adopted this approach. However, intermittent encryption is flawed. In this blog post, I will introduce White Phoenix, a tool my team built that takes advantage of the fact that those files aren’t entirely encrypted and can, in the right circumstances, salvage some content from the unencrypted parts of the files. While we will primarily focus on BlackCat, it’s important to note that White Phoenix is also effective against other ransomware.
Intermittent Encryption: What? Why? Who?
Intermittent encryption is when ransomware forgoes encrypting the entirety of every file, instead only encrypting part of each file, often blocks of a fixed size or only the beginning of targeted files.
There are several reasons attackers choose intermittent encryption over full encryption.
The most obvious is speed. Because files are only partially encrypted, intermittent encryption requires less time spent on each file, allowing the ransomware to impact more files in less time. This means that even if the ransomware is stopped before running to completion, more files will be encrypted, creating a more significant impact and making it more likely the ransomware will end up damaging critical files.
Moreover, encryption speed can also be used as a selling point. Ransomware providers can claim to have faster encryption to persuade affiliates to choose them over other providers.
Additionally, some security solutions make use of the amount of content being written to disk by a process in their heuristics to identify ransomware. With intermittent encryption, less content is written, and therefore, there is a smaller chance that ransomware will trigger such detections.
Several different ransomware groups have adopted intermittent encryption. Altogether, the victims of these ransomware groups number in the hundreds (based on the numbers in their respective leak sites). The victims span various organizations, such as banks, universities and hospitals. Arguably the most notable ransomware group is BlackCat (a.k.a. ALPHV). This ransomware is considered by many to be the most sophisticated on the market. The malware has a variety of features to justify this claim, such as:
- The group was an early adopter of writing malware in Rust (alongside other notable malware such as FickerStealer).
- It requires a specific input to decrypt the malware’s configuration, which serves as an anti-analysis technique, preventing both automated dynamic analysis in sandboxing technologies like Cuckoo Sandbox and automated static analysis such as config extraction.
- Intermittent encryption is in itself a feature that makes the malware notable. However, the group takes it even further with highly configurable encryption modes that dictate what parts of each file to encrypt.
BlackCat Encryption Modes
BlackCat can be configured with any of six different encryption modes. All the modes loosely fit the following structure:
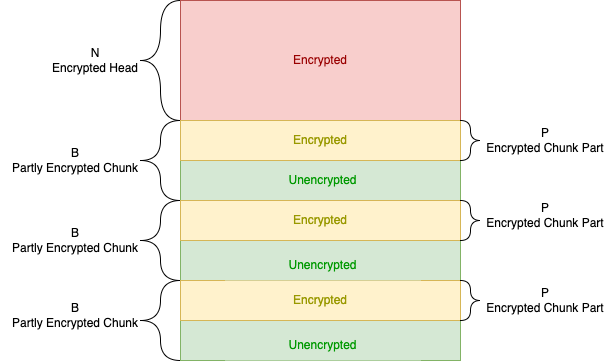
Figure 1: BlackCat encryption mode structure
As you can see in Figure 1, in many of these encryption modes, the encryption starts from the beginning of the file until some fixed point. We represent the size of the encrypted head of the file with the letter “N.”
In other encryption modes, the file — or at least part of the file — is broken into chunks of a fixed size, with the beginning of each chunk encrypted. We mark the size of each chunk with the letter “B,” and the size of the encrypted portion of each chunk is marked with “P.”
We marked the first N encrypted bytes with the color red and each encrypted portion P of each chunk in yellow. The remaining unencrypted parts are in green.
The six possible encryption modes are as follows:
- Full: Essentially just traditional encryption (i.e., the whole file gets encrypted). This would mean the red portion covers the entire file in our diagram, or N is equal to infinity.
- Head Only: Only the first N bytes are encrypted. Following the diagram, that would be the same as N being set to some positive integer and P equaling zero, making the value of B irrelevant. Or simply, no yellow color.
- Dot Pattern: In this mode, N is equal to zero. The file is broken into chunks of a fixed size B, with the first P bytes of each chunk being encrypted. This would be the same in our diagram as not having a red portion.
- Smart Pattern: This is where things get a bit complicated. The first N bytes are encrypted (red), with the rest of the file split into 10 equal-sized blocks, with the first P percent of each block encrypted (yellow).
- Advanced Smart Pattern: This mode is very similar to Smart Pattern. The difference is that B is also configurable, meaning rather than 10 equally sized blocks, the threat actors can create as many blocks as they want with any size. The first N bytes are encrypted (red), and the remainder of the file is broken into equally sized blocks. Here, unlike in Smart Pattern, the blocks are of whatever size was defined for B. Finally, the first P percent of each block is encrypted (yellow).
- Auto: The final encryption mode encrypts the files differently depending on the size and type of files. For files less than 10MB, Full encryption is used. For files between 10MB and 10GB, Advanced Smart Pattern is used with parameters (N, P, B) varying depending on the exact size of the file. Finally, for files larger than 10GB, the Dot Pattern is used, with parameters changing depending on the precise file size.
As you can see, most of the encryption modes can end up leaving a large portion of the files unencrypted. This means that for some file formats, we can extract data from the non-encrypted parts of the files and recover some of the data from there, as you will see below.
PDF 101
During our research, we primarily focused on recovering text and images from encrypted PDF files. To understand how we’re able to recover content from these files, it’s essential to understand some of the basics of the PDF file structure. We won’t ask you to read the PDF format specification, as just the section explaining how text appears in the PDF structure is over 50 pages long. Instead, I will simplify things and skip over a lot of details.
The general structure of a PDF file is a header, a body and a footer. The body is composed of a list of objects. Each object starts with a pair of numbers followed by the string “obj,” all separated by spaces. The first number is a unique number representing the object number, and the second number is usually zero. Objects end with the string “endobj.” So, an example for object number four in a PDF file might look something like this:
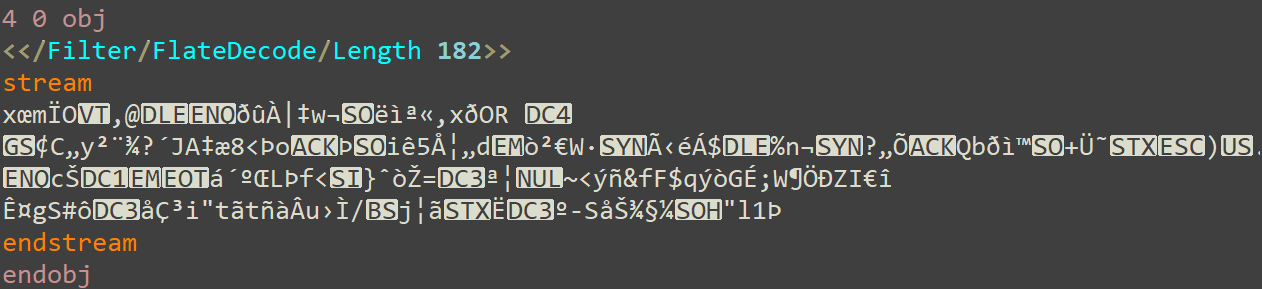
Figure 2: Example PDF stream object
There are many kinds of objects in the PDF format. The most important one for our purposes is the stream object. Stream objects have two parts: a dictionary describing the stream and the content of the stream itself. The dictionary appears surrounded by << , >>. The stream content starts with the string “stream” and ends with the string “endstream.”
In the example above, the dictionary has two keys: Length and Filter. Length refers to the size of the stream content, which in our example is 182 bytes. Filter indicates which compression and encoding algorithms were applied to the content of the stream. The most common by far, and the one in our example, is the FlateDecode filter. FlateDecode refers to a common compression algorithm used in many file formats known as DEFLATE.
Recovering Data from Encrypted PDF Files
As we’ve discussed previously, almost all of the encryption modes used by BlackCat can potentially leave a significant amount of the content in files unaffected. Specifically, in the case of PDF files, this means many objects will remain completely intact. We can extract these untouched objects from the PDFs and save any valuable data we find.
Both images and text appear in stream objects in PDF files. So, to recover them from an encrypted PDF document, we need to go over the stream objects. Images usually occur as the content of stream objects. That means we can generally recover them by removing whatever filters are applied.
Unfortunately, recovering text requires some more work. In simpler cases, the text is broken up into chunks inside the stream. In those cases, we need to identify all the chunks and concatenate the content of every chunk together. The following image is an example of part of a PDF stream containing the text “This is an example of a simple text object in a PDF.” As you can see, the text is broken up into different chunks surrounded by parentheses:

Figure 3: Example of a simple text stream
Those who participated in the INTENT Summit 2022 CTF might remember a challenge called “Text Rendering Is Hard,” which showcased a more complicated variation of how text is stored in PDF files. In the more complex cases, the text is encoded using hex followed by a CMAP (character mapping), in addition to being broken up into chunks. To help illustrate this, the following images contain a text stream and a character mapping:
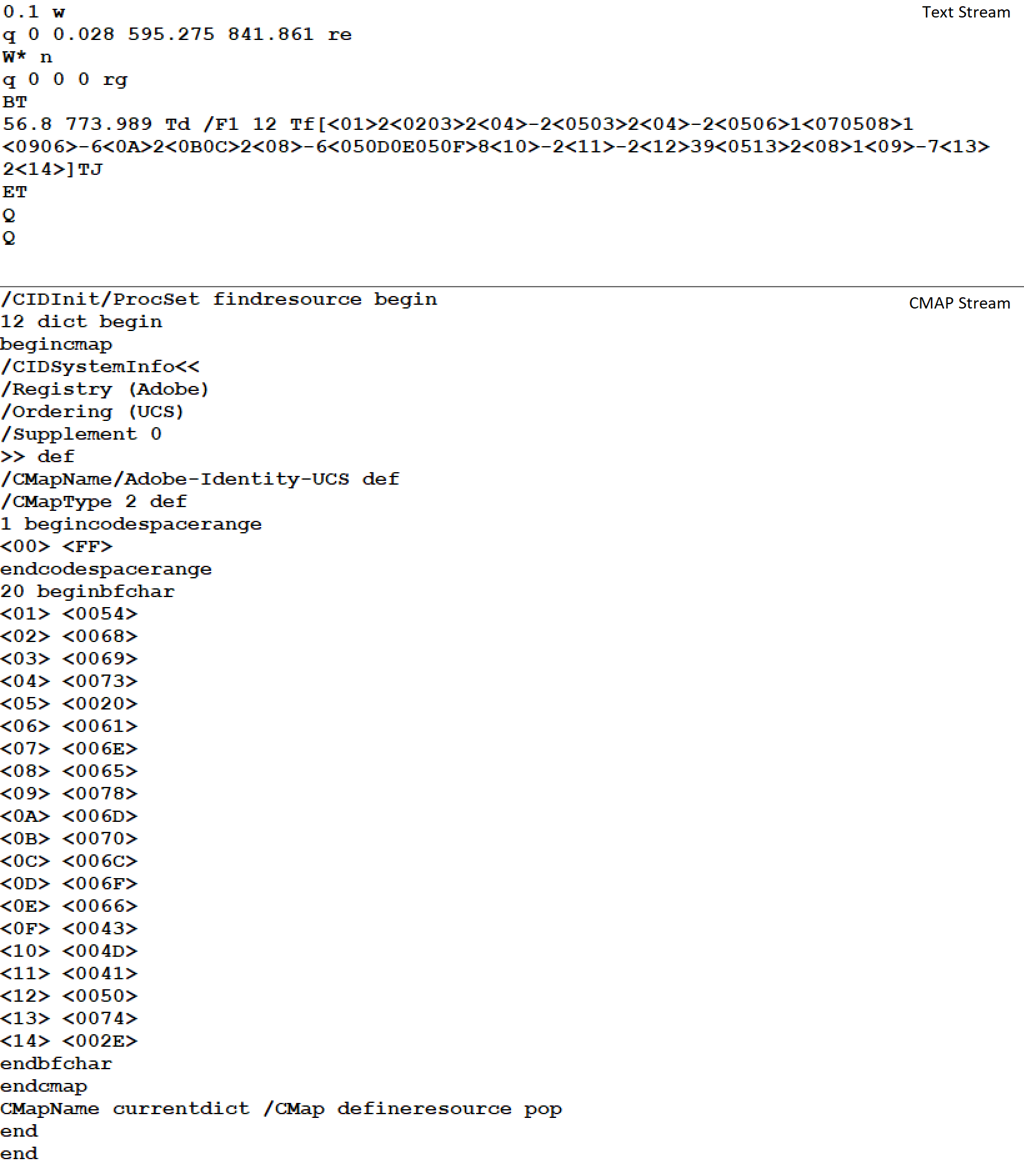
Figure 4: Example CMAP text stream (Top) and associated CMAP stream (Bottom)
The top part shows the stream containing the encoded text, and the bottom part shows the stream containing the CMAP used for the encoding. In the cases that use CMAP, the chunks are surrounded by <> instead of (). To understand what the text is supposed to be, we need to find the matching values in the CMAP object. For instance, the first character in the text object is <01>. Looking in the CMAP object, we see <01> is mapped to <0054>. Once we find the mapped value for the character, all we need to do is decode from hex. In this case, 54 is the hex value for the character “T,” so the first character in our text is “T.” Repeating this for the rest of the characters will give us the text “This is an example of CMAP text.”
For the cases where text is stored as CMAP objects, to recover the text, neither the text nor the CMAP objects can be encrypted. Sometimes, though rare, the text is mapped using hex. For example, the character “A” would be encoded into 41, and then 41 would be mapped again to 41. In these lucky cases, we can recover the text even if the mapping can’t be recovered.
Other File Formats
We can recover other file types in addition to PDF. Many file formats, including many formats used by Microsoft Office, are, in fact, special cases of the zip file format. Again, we will skip most of the details and simplify things.
In short, every file compressed into a zip has an entry in the zip structure that starts with PK\x03\x04. If you take a partially encrypted zip file and erase everything from the beginning until the first PK\x03\x04, you can still open the zip with 7zip and extract the contents of all the non-encrypted files. In Office documents, these compressed files are often XML files. As a result, it’s possible, under the right conditions, to recover some data from Office documents that BlackCat ransomware has encrypted.
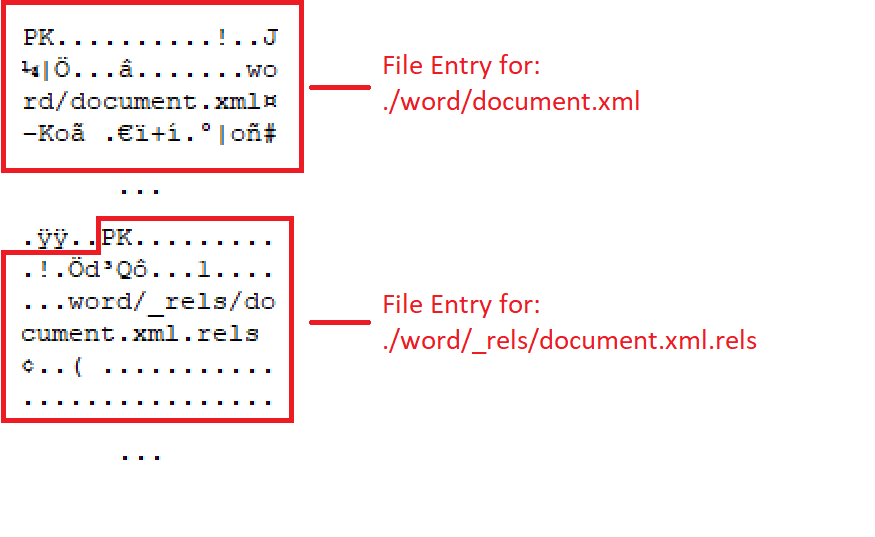
Figure 5: Example file entries in a zip file
During our investigation, we were able to create a valid XLSX file with some of the content of an encrypted file by taking the following steps:
- Using 7zip and a hex editor in the method described above, we extracted the XML files unaffected by the encryption from the encrypted XLSX.
- We then created and unzipped a new, empty XLSX file.
- We replaced the files extracted from the new XLSX with the matching files from the encrypted XLSX we managed to recover.
- Finally, we recompressed the files and saved them with the XLSX extension.
We were able to then open the new file with Excel and view some of the data from the encrypted file.
White Phoenix — Recovery Tool
As we’ve seen, sufficient knowledge about various file formats makes it possible to recover data from intermittently encrypted documents. To help automate the process, we built White Phoenix, a Python script that can automate the recovery process.
We chose “white” to contrast the many ransomware groups that use the word “black” in their names, such as BlackCat, BlackByte and Lockbit Black. “Phoenix” was chosen because we hope this tool will help “resurrect” (like a phoenix) companies after suffering a ransomware attack.
The tool needs 2 arguments to run: the path to the file and the path to a folder to save the recovered content. The file type, if supported is recognized automatically. See below a complete list of the types of files this tool supports.
In the case of PDF files, we implemented all of the logic described above to recover text and images. We built it so that each recovered object is saved as a separate file named after the source object. For text objects that use CMAP, we also indicate which object provided the mapping.
For the various zip-based formats we support, we only implemented the unzipping step. In the case of Office documents, we can follow the steps described earlier to try and manually recover part of the encrypted document. However, there is no guarantee the resulting document will be valid. Alternatively, we can find the recovered images (if there were any) in the following paths, with the exact path depending on the file type:
- ./word/media/
- ./xl/media/
- ./ppt/media/
For Word documents, we can find the text in the following XML file:
- ./word/document.xml
Excel documents store their sheets in the folder:
- ./xl/worksheets/
However, text used in the sheets is often stored in a separate file:
- ./xl/sharedStrings.xml
Finally, for PowerPoint documents, the slides are stored in the folder:
- ./ppt/slides/
Conclusion
White Phoenix supports PDFs, Microsoft Office documents and zip files. But other formats, such as video and audio files, may also be recoverable. We encourage the community to contribute to this tool and help improve things further.
We often think of threat actors exploiting bugs in software to perform malicious activities, such as gaining unauthorized access to networks or escalating privileges. But malware is ultimately a piece of software written by people too. And just like the software bugs exploited by the threat actors, we can leverage bugs in malware.
Intermittent encryption starts to blur the line between corrupting files and making files truly unusable. Arguably, the idea of intermittent encryption turned out to be a mistake. Just like there are many tools to help recover data from corrupted files, there can be tools to recover data from files that have undergone intermittent encryption.
Link to White Phoenix recovery tool:
https://github.com/cyberark/White-Phoenix
List of supported ransomware:
- BlackCat/ALPHV
- Play ransomware
- Qilin/Agenda
- BianLian
- DarkBit
List of supported file types:
- Word formats: docx, docm, dotx, dotm, odt
- Excel formats: xlsx, xlsm, xltx, xltm, xlsb, xlam, ods
- PowerPoint formats: pptx, pptm, ptox, potm, ppsx, ppsm, odp
- Zip






















