

TL;DR
After Docker released a fix [1] for CVE-2021-21284 [2], it unintentionally created a new vulnerability that allows a low-privileged user on the host to execute files from Docker images. Thus, an attacker may execute files with capabilities or setuid files in order to escalate its privileges up to root level.
Also, few Microsoft Docker images contained files with capabilities that can be leveraged to escalate one’s privileges in a Linux system.
Overview
Linux Capabilities
In the beginning, there were only root and a few other users. All these other users were low privileged and very limited. Root, on the other hand, was powerful and capable of all…
In more technical words (and maybe less biblical ☺), traditionally, Unix had two kinds of processes: privileged processes, which have eUID 0, and non-privileged processes, with a non-zero eUID. Thus, if a binary had to use some privileged resources, the process would have had to be run as eUID 0, a.k.a root.
Starting with Linux kernel 2.2, the kernel developers decided to make a mechanism different than the binary root/non-root and added the Linux capabilities to the kernel. This is probably the most important thing to understand regarding the vulnerability, which I will discuss later in this post. Linux capabilities is a powerful mechanism that lets any system administrator accomplish a least privilege security scheme.
You may wonder how it helps us as users and administrators. Well, remember setuid binaries? [“Yes; of course we remember!” the readers cheered]. Do you remember how dangerous those binaries may be? [“YES!” they cheered once more]. So, that is how capabilities come to our aid. Instead of using suid binaries that potentially use full root privileges, one can use Linux capabilities that will make it possible to run a certain operation without the need of becoming the full, all-powerful root user.
Process Capabilities vs. File Capabilities
When talking about Linux capabilities, we must distinguish between process capabilities and file capabilities. Though they have much in common, they are two different things.
Process capabilities
Let’s start with process capabilities. Every single process in a Linux system, without exception, has (at the time of writing this blog post) five different sets of capabilities — ambient, permitted, effective, inheritable and bounding. Those sets determine what operation a process may or may not do. Here we will discuss only three of them, as there is great documentation on the official Linux man-pages [3].
- effective – The set that is being checked by the kernel to determine if a process may do a certain operation.
- permitted – A limiting superset for the effective set. A process may not obtain any capabilities that are not in the permitted set.
- bounding – Every time a new process is spawned, it gains its capabilities during the execve. As this set’s name implies, it determines the capability bounds of the new child process. In other words, it limits the capabilities a new process may gain.
Note that the easy way to differentiate between the “permitted” set and the “bounding” set is that “permitted” is the set of capabilities that a process may have, and “bounding” is the set of capabilities a process can have.
File capabilities
Since the release of Linux kernel 2.6.24, it has been possible to attach capabilities to files. Those capabilities are stored as extended attributes of a file in the filesystem. It means that when a binary is being executed, the kernel checks the capabilities attached to it and determines the capabilities that the new process should have. There are three types of file capabilities: effective, inheritable and permitted. Like in the previous section about process capabilities, you may read more at the Linux man-pages. Here is the necessary explanation for us:
- permitted – This set of capabilities, will be examined by the time of the binary execution to determine what will the permitted capability set of the new process contain.
- effective – Here is an exception. The effective is actually only one bit. When the bit is set, when a new process is spawned, its effective (the process capability set) will be the same as the process’ permitted set.
Leveraging file capabilities
Let’s take the ping command for explaining this concept. For several years in Linux, in order to use raw sockets, you had to be root. So, when ping, which uses raw sockets, was created, it was built as a suid binary for the executable to work. It is not good practice to give an executable like ping such high permissions because if there were an exploitable bug in the binary, attackers could elevate their privileges to root. That is why when capabilities were introduced, ping became a regular binary with CAP_NET_RAW file capability attached to it. That way, when ping was executed, it had the ability to create and use raw sockets but without all the other unnecessary root privileges.

The TOP SECRET Formula
Below are the formulas for how every set of a new process’s capabilities is determined. Pay close attention to the P'(permitted) and the p'(effective) sets and how the file capabilities may affect those sets.
P() – Represents the process before the execve(). It is the capability set’s value of the parent.
P'() – Represents the process after the execve().
F() – Represents the executed file attached capability sets.
![]()
Figure 1 – Transformation of capabilities during execve(). From Capabilities(7) man pages < https://man7.org/linux/man-pages/man7/capabilities.7.html>
Capabilities and Docker
Capabilities are an inseparable part of Docker containers. Take the root user inside a default Docker container, for example. Unless you specified the ––privileged option when running the container, processes of root inside the container will have a very limited set of capabilities. This is how Docker restricts the operations that can be done from the inside as a way of mitigating against container escape.
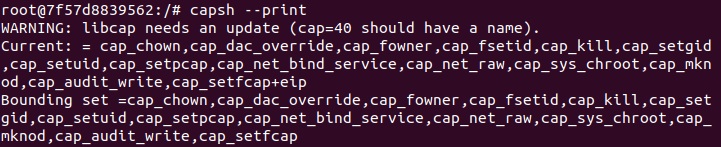
Figure 2 – Docker default container’s capability sets
For example, let’s take the case of CAP_SYS_MODULE. If a process inside a container has this capability, in theory, the process may insert a new loadable kernel module into the running kernel. And because the host shares the kernel with the container, it means the contained process is escaping to the host itself.
There Is No Success Without Failure
What About Crafted Image with Capable Files?
So, in theory, if an attacker has the ability to mount an image file that, when mounted, contains a binary with file capabilities, it can be used to execute any process with any capability and escalate privileges immediately.
Turns out it is not that simple. As you probably know, only root (or to be exact, only process with CAP_SYS_ADMIN) may use mount. So, this led me to another idea…
The nosuid Problem
What if the attacker had physical access to the machine and could just connect a USB storage device to it? In the vast majority of distros, when a new USB device is connected, it is automatically mounted by the system. So, let’s just stick a d.o.k. (disk-on-key) with a file with SYS_ADMIN capabilities and that is it! We won!
Or did we?
When mounting a new device to the system, it is a possibility to use the mount option nosuid. nosuid tells the kernel to ignore every setuid bit when executing files from the mounted filesystem.
This automatic mount has the mount option nosuid, which is a logical thing to do, as (obviously) any attacker can craft any binary he would like, put it as a suid executable, add it in a USB and just run it. Turns out, nosuid also affects file capabilities. Every time a file with capabilities is being executed, the kernel checks if it lies on a nosuid filesystem, and if so, the capabilities are just being ignored during execution.
The Overlay Filesystem
In the quest to find a way to bypass such annoying (and smart) mitigations, I found a disclosure of a vulnerability in overlayFS, which does exactly what I wanted in some Ubuntu versions and flavors. As it is out of the scope for this blog, here is the link to the full disclosure, so you may read more if you like [4].
That vulnerability gave me an idea. Who uses overlayFS more than any other? Docker! Let’s see if maybe the Docker engine uses overlayFS in such way an attacker can abuse. While testing if there is a way to copy the capable file from a USB drive to the root filesystem, I accidentally tried to copy a file from /path/to/docker/image/rootfs/file to /home/user/ as a regular user. Though the file was copied without its capabilities, I noticed I had permission to access the file — access I should not have as an unprivileged user.
The Gift of the 701 Permissions
From that point forward, I tried to understand why it worked for me. When I told a colleague of mine about it, he tried to reproduce the problem but got an error while trying to access the capable file in /var/lib/docker/overlay2/. So, why was I able to do it, and he was not? The only difference between our two machines was the Docker engine version.
After looking at the release notes of every version that was released from his Docker version to mine, I saw a potentially problematic fix that may have caused the bug I used to access the files. We will not get into the fix itself, but the main thing they did was change some directories permissions under /var/lib/docker from 700 to 701. One of the changed directories stored all saved Docker images, /var/lib/docker/overlay2/ (Or in case of other storage driver, it will be a different name but have the same outcome). Now, every user can execute files from inside this directory and has access to the Docker images on the machine.
Video 1 – Docker permissions difference between versions
Attack Vectors
There are a few ways to abuse this new access Docker engine gave us. In this section, I will talk about two attack vectors I used as proof of concept.
Root in a Container — Low Privileges on the Host
Another way to abuse this “feature” is to create the wanted capable file by yourself. This technique utilizes a low-privileges user on the host and a root user inside a container (default configuration in Docker’s containers), which runs on the same host. Here is the attack vector step by step:
- With the root inside the container, an attacker can create an executable that sets its uid and gid to 0 and executing /bin/bash.
- Using setcap(8), the attacker will now attach CAP_SETUID and CAP_SETGID to the executable from the previous step. This step works because in the default Docker containers, root has CAP_SETFCAP, which allows him to use setcap(8).
- All the attacker needs to do from here is just execute the file. The attacker has now escalated his privileges to root on the host.
I could have easily used the setuid permissions on the file, as its owner is root. It would have worked the same. There were two reasons I chose to use Linux capabilities. For starters, Linux capabilities are not being monitored as much as suid binaries, so it is much quieter that way. The second reason is that I had a lot of time to think about Linux capabilities and how to use them for attacking, so it was the first thing on my mind when I realized I had the option.
Video 2 – Attack vector 1 PoC
Microsoft MSsql Server
Sometimes, you won’t be able to access a container that runs on the host you are already on. In that case, there is a chance that the server you gained access to has some Docker images with capable files already on it.
After scouting 2500 Docker images from DockerHub, there was a surprisingly large number of images that contained files with capabilities. The most notable one was Microsoft’s mssql server [5]. The mssql Docker image had a file with CAP_SYS_PTRACE capability attached to it. What CAP_SYS_PTRACE is allowing, is to trace any given process running on the machine. That file was gdb.
Having the ability to execute gdb with CAP_SYS_PTRACE on the host using a low-privileges user practically gives the user root permissions, as he can now attach, peek, kill and modify any process, even if it’s running in root context.
Video 3 – Attack vector 2 PoC
Why Does it Work?
You made it through to here. Congrats! Now, some of you may be asking yourselves whether containers should be isolated. The short answer is “yes.” The longer answer is that this is more complicated than just a yes or no question. Processes inside containers should not escape the container, but the host can and may access the insides of the container. So, why is it so problematic for us to access it? I will get to it later. First, we need to talk a bit about namespaces.
Docker engine uses different namespaces [6] and cgroups [7] to isolate the container from the outside. Docker engine only creates some namespaces, such as pid, mnt and more. However, Docker engine does not create a new user namespace by default.
Namespaced File Capabilities
There is an option to encode a user namespace inside the extended attributes (the file capabilities). That way, when a user executes a capable file, the kernel will check if the namespace encoded in the extended attributes is the same as the current user namespace. If so, the capabilities will be granted; if not, the kernel will not grant capabilities during the execution.
Important note: user namespaces are nested. That means that every namespace has a father, child or both. So, if someone tries to run a capable file with a root-namespace capabilities, it will work even if it is a child user namespace of the root namespace.
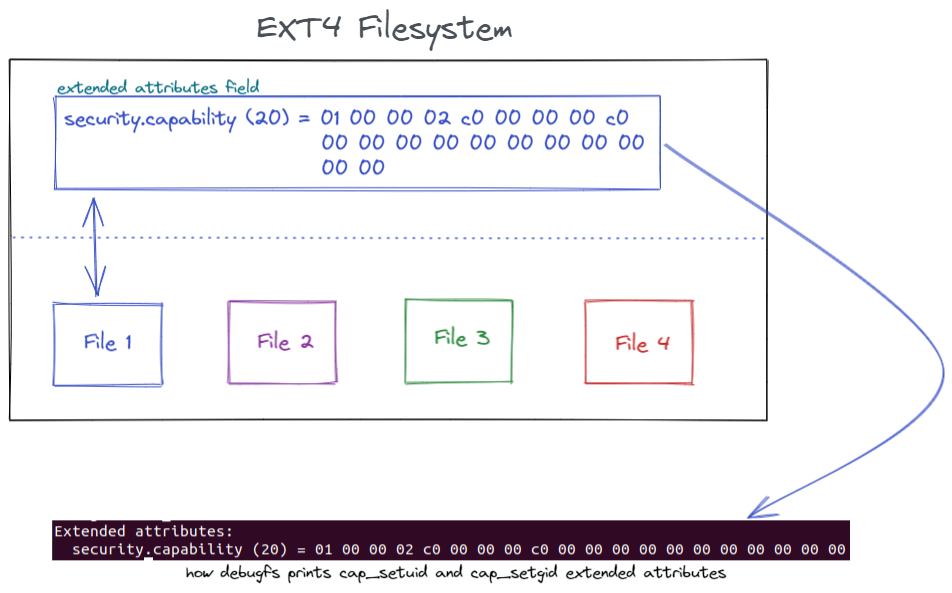
Figure 3 – Visual representation of extended attributes
setcap, the command we use when ordering the set capabilities to files, uses the kernel setxattr(2) [8] system call. And when setxattr inspects a user namespace that is not the root namespace, it encodes the current one to the file capabilities.
Back To Docker
As mentioned earlier, Docker engine does not use different user namespace. You have probably already guessed it: the capabilities inside the container itself are the same capabilities on the host. And the gift of 701 allows us to execute files with those capabilities, even though the creator is a Docker container.
Mitigation
Docker fixed the permissions problem in Docker engine version 20.10.9 and assigned CVE-2021-41091 for this vulnerability. So, the first and best mitigation is to update the Docker engine.
Another possible and easy-to-achieve mitigation for these attack vectors, which relies on file capabilities, is to run the containers in a different user namespace. In a different namespace, setxattr will create a namespaced capabilities. Take Docker rootless mode, for example. It runs as a non-root user in a different user namespace. When setting file capabilities, it is automatically encoded with the current namespace. Note that this will not fix the problem for suid binaries.
In any case, the best recommendation would be to check every new image you use. All you need to do is search for capable files or suid files inside the image. Use the command getcap -r /path/to/image/root/fs/ 2>/dev/null to get a great output with all the capable files in the image.

Figure 4 – getcap output example
Microsoft has assigned CVE-2022-23276 to the capable gdb binary issue in their Docker images and released new versions of the images. However, the previous vulnerable images are still available, and it is important to update them in case you are using one of them.
Summary
This whole process started as research about Linux capabilities and how they may be abused or the way they are handled in the kernel. After a while, I started looking at different branches that came up during the research itself. One of the branches unintentionally led me into finding an insufficient permissions handling vulnerability in Docker engine.
As for the Linux capabilities, be aware of how it may be a very strong solution for least privileged execution. Capabilities divide the privileges Linux had into dozens of fine-grained permissions to specific operations in the system. But, like any other thing in life, you should know how and when to use it. When used carelessly, as we saw in Microsoft’s mssql Docker image and Docker’s fix for another security issue, it can open a new attack surface that was not there before.
Disclosure Timeline
08/04/2021 – Vulnerability reported to Microsoft
08/11/2021 – Vulnerability reported to Docker
09/28/2021 – Docker acknowledged the reported issue
10/04/2021 – Docker released a fix for the vulnerability (CVE-2021-41091)
10/21/2021 – Microsoft acknowledged the reported issue
02/08/2022 – Microsoft assigned CVE-2022-23276
References
[1] – Docker’s fix for previous vulnerability – https://github.com/moby/moby/commit/e908cc39018c015084ffbffbc5703ccba5c2fbb7
[2] – CVE-2021-21284 – https://github.com/moby/moby/security/advisories/GHSA-7452-xqpj-6rpc
[3] capabilities(7) man page – https://man7.org/linux/man-pages/man7/capabilities.7.html
[4] SSD Advisory OverlayFS PE – https://ssd-disclosure.com/ssd-advisory-overlayfs-pe/
[5] Microsoft’s SQL Server Docker image on DockerHub – https://hub.docker.com/_/microsoft-mssql-server
[6] Nnamespaces(7) man page – https://man7.org/linux/man-pages/man7/namespaces.7.html
[7] cgroups(7) man page – https://man7.org/linux/man-pages/man7/cgroups.7.html
[8] setxattr(2) man page – https://man7.org/linux/man-pages/man2/setxattr.2.html






















